
Em 1964, o matemático e cientista da computação Woodrow Bledsoe tentou pela primeira vez comparar os rostos dos suspeitos de crimes com as fotos policiais. Ele mediu as distâncias entre diferentes características faciais em fotografias impressas e as inseriu em um programa de computador. Seus rudimentares sucessos desencadeariam décadas de pesquisa em máquinas de ensino para reconhecer rostos humanos.
Agora, um novo estudo mostra o quanto esse empreendimento corroeu nossa privacidade. Não apenas alimentou uma ferramenta de vigilância cada vez mais poderosa. A última geração de reconhecimento facial baseado em deep learning afetou completamente nossas normas de consentimento.
Deborah Raji, pesquisadora da organização sem fins lucrativos Mozilla, e Genevieve Fried, que assessora membros do Congresso dos Estados Unidos sobre responsabilidade algorítmica, examinaram mais de 130 conjuntos de dados de reconhecimento facial compilados ao longo de 43 anos. Eles descobriram que os pesquisadores, impulsionados pela explosão dos requisitos de dados do deep learning, gradualmente abandonaram o pedido de consentimento das pessoas. Com isso, cada vez mais fotos pessoais passaram a ser incorporadas a sistemas de vigilância sem o conhecimento dos indivíduos.
Isso também gerou conjuntos de dados muito mais confusos: eles podem incluir fotos de menores sem querer, usar rótulos racistas e sexistas ou ter qualidade e iluminação inconsistentes. A tendência pode ajudar a explicar o número crescente de casos em que os sistemas de reconhecimento facial falharam com consequências preocupantes, como a falsa prisão de dois homens negros na área de Detroit no ano passado.
As pessoas eram extremamente cautelosas ao coletar, documentar e verificar os dados faciais no início, diz Raji. “Agora não ligamos mais. Tudo isso foi abandonado”, diz ela. “Você simplesmente não consegue acompanhar um milhão de rostos. Depois de um certo ponto, você não pode nem fingir que tem o controle”.
Um histórico de dados de reconhecimento facial
Os pesquisadores identificaram quatro grandes eras de reconhecimento facial, cada uma impulsionada por um desejo crescente de melhorar a tecnologia. A primeira fase, que durou até a década de 1990, foi amplamente caracterizada por métodos manuais intensivos e computacionalmente lentos.
Mas então, estimulado pela percepção de que o reconhecimento facial poderia rastrear e identificar indivíduos de forma mais eficaz do que as impressões digitais, o Departamento de Defesa dos EUA investiu US $ 6,5 milhões na criação do primeiro conjunto de dados de rosto em grande escala. Mais de 15 sessões de fotografia em três anos, o projeto capturou 14.126 imagens de 1.199 indivíduos. O banco de dados da Face Recognition Technology (FERET) foi lançado em 1996.
As quatro eras do reconhecimento facial
Os conjuntos de dados de reconhecimento facial aumentaram exponencialmente em tamanho à medida que os pesquisadores buscavam melhorar a precisão da tecnologia.
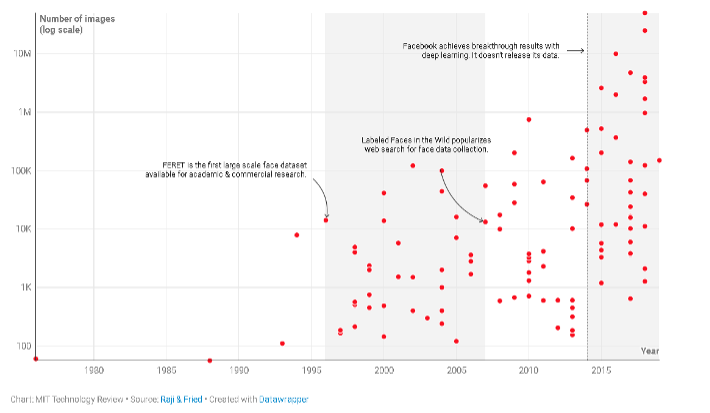
Gráfico: Número de imagens (Escala logarítmica). FERET é o primeiro conjunto de dados de rosto em grande escala disponível para pesquisa acadêmica e comercial. O Labeled Faces in the Wild populariza a pesquisa na web para a coleta de dados de rosto. O Facebook alcança resultados revolucionários com deep learning. Não divulga seus dados.
Na década seguinte, houve um aumento nas pesquisas acadêmicas e comerciais de reconhecimento facial, e muitos mais conjuntos de dados foram criados. A grande maioria foi obtida por meio de sessões de fotos como a da FERET e teve o consentimento total dos participantes. Muitos também incluíram metadados meticulosos, diz Raji, como a idade e etnia dos assuntos ou informações de iluminação. Mas esses primeiros sistemas tiveram dificuldades em configurações do mundo real, o que levou os pesquisadores a buscar conjuntos de dados maiores e mais diversos.
Em 2007, o lançamento do conjunto de dados Labeled Faces in the Wild (LFW) abriu as comportas para a coleta de dados por meio de pesquisa na web. Os pesquisadores começaram a baixar imagens diretamente do Google, Flickr e Yahoo, sem preocupação com o consentimento. Um conjunto de dados subsequente compilado por outros pesquisadores, chamado LFW +, também flexibilizou os padrões em torno da inclusão de menores, usando fotos encontradas com termos de pesquisa como “bebê”, “juvenil” e “adolescente” para aumentar a diversidade. Esse processo tornou possível criar conjuntos de dados significativamente maiores em um curto espaço de tempo, mas o reconhecimento facial ainda enfrentou muitos dos mesmos desafios de antes. Isso levou os pesquisadores a buscarem ainda mais métodos e dados para superar o fraco desempenho da tecnologia.
Distribuição da fonte de dados de reconhecimento facial por época
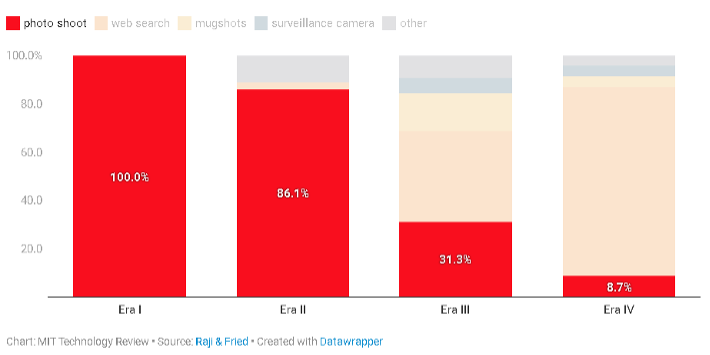
Sessão de fotos, pesquisa na web, fotos policiais, câmeras de vigilância, outros. Era I, Era II, Era III, Era IV.
Então, em 2014, o Facebook usou suas fotos de usuário para treinar um modelo de deep learning chamado DeepFace. Embora a empresa nunca tenha divulgado o conjunto de dados, o desempenho sobre-humano do sistema elevou o deep learning ao método de facto para análise de rostos. Foi quando a verificação manual e a rotulagem se tornaram quase impossíveis, pois os conjuntos de dados aumentaram para dezenas de milhões de fotos, diz Raji. É também quando fenômenos realmente estranhos começam a aparecer, como rótulos gerados automaticamente que incluem terminologia ofensiva.
A maneira como os conjuntos de dados era usada também começou a mudar nessa época. Em vez de tentar combinar indivíduos, novos modelos começaram a se concentrar mais na classificação. “Em vez de dizer: ‘isso é a foto de Karen? Sim ou não,’ transformou-se em ‘Vamos prever a personalidade de Karen, ou sua etnia ‘, e encaixar pessoas nessas categorias”, diz Raji.
Amba Kak, diretora de política global da AI Now, que não participou da pesquisa, diz que o artigo oferece uma imagem nítida de como a indústria da biometria evoluiu. O deep learning pode ter poupado a tecnologia de algumas de suas lutas, mas “esse avanço tecnológico também teve um custo”, diz ela. “São levantados todos esses problemas com os quais agora estamos bastante familiarizados: consentimento, extração, questões de Propriedade Intelectual, privacidade”.
Perigos que geram perigos
Raji diz que a investigação dos dados a deixou gravemente preocupada com o reconhecimento facial baseado no deep learning.
“É muito mais perigoso”, diz ela. “O requisito de dados força você a coletar informações extremamente confidenciais sobre, no mínimo, dezenas de milhares de pessoas. Isso o força a violar a privacidade delas. Isso em si é uma base de perigo. E então estamos acumulando todas essas informações que você não pode controlar para construir algo que provavelmente funcionará de maneiras que você nem pode prever. Essa é realmente a natureza de onde estamos”.
Ela espera que o artigo provoque os pesquisadores a refletirem sobre o equilíbrio entre os ganhos de desempenho derivados do deep learning e a perda de consentimento, verificação meticulosa de dados e documentação completa. “valeu a pena abandonar todas essas práticas para fazer um deep learning?” diz ela.
Ela pede àqueles que desejam continuar construindo o reconhecimento facial a considerarem o desenvolvimento de técnicas diferentes: “para nós realmente tentarmos usar esta ferramenta sem machucar as pessoas, será necessário repensar tudo o que sabemos sobre ela”.
Correção, 15 de fevereiro de 2021: uma versão anterior do artigo afirmava que o conjunto de dados Labeled Faces in the Wild (LFW) “flexibilizou os padrões em torno da inclusão de menores”. Na verdade, era o conjunto de dados LFW +, que foi compilado posteriormente por um grupo diferente de pesquisadores.


